리눅스 서버에서 데이터베이스를 직접 운영하면 관리형 DB(RDS 등) 대비 비용은 절감되지만, 그만큼 직접 해결해야 할 문제가 많습니다. 이 글에서는 실무에서 자주 마주치는 데이터베이스 운영 문제를 체계적으로 정리하고, 각각의 해결 방법을 안내합니다.
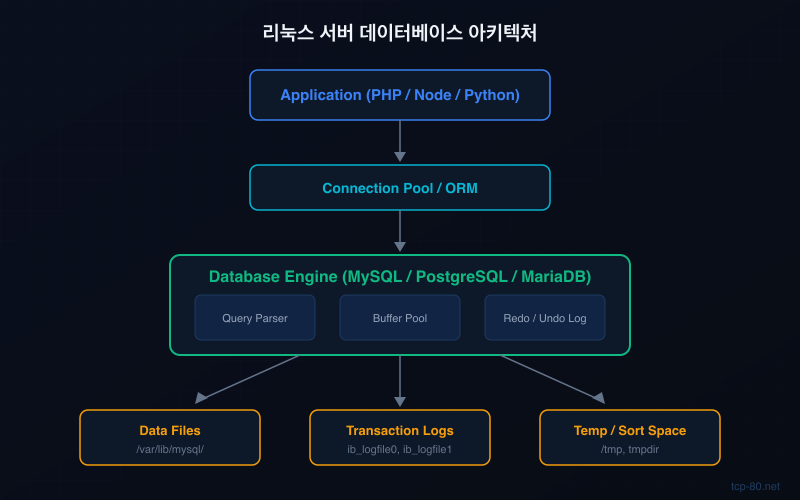
1. 메모리 부족으로 인한 성능 저하
데이터베이스 성능 문제의 가장 흔한 원인은 메모리 부족입니다. 특히 InnoDB의 Buffer Pool 크기가 부족하면 디스크 I/O가 급증하면서 전체 쿼리 속도가 느려집니다.
증상
- 쿼리 응답 시간이 점점 길어짐
iostat에서 디스크 사용률 90% 이상free -h에서 available 메모리가 거의 없음- OOM Killer가 DB 프로세스를 강제 종료
해결 방법
# 현재 Buffer Pool 크기 확인
mysql -e "SHOW VARIABLES LIKE 'innodb_buffer_pool_size';"
# 전체 메모리의 60~70%를 Buffer Pool에 할당 (예: 8GB 서버)
# /etc/mysql/mysql.conf.d/mysqld.cnf 에 추가
innodb_buffer_pool_size = 5G
innodb_buffer_pool_instances = 4
# OOM Killer 방지 — DB 프로세스 우선순위 조정
echo -17 > /proc/$(pidof mysqld)/oom_adj
핵심 포인트: 서버 메모리가 4GB 이하라면 데이터베이스 전용 서버로 쓰기엔 부족합니다. 최소 8GB 이상을 권장합니다.
2. 디스크 I/O 병목
HDD를 사용하는 서버에서 데이터베이스를 운영하면 랜덤 읽기/쓰기 성능이 심각하게 떨어집니다. 특히 트래픽이 몰리는 시간대에 쿼리 지연이 발생합니다.
진단 방법
# 디스크 I/O 상태 확인
iostat -xz 1 5
# 주요 지표:
# %util — 90% 이상이면 병목
# await — 10ms 이상이면 지연 발생 중
# r/s, w/s — 초당 읽기/쓰기 횟수
# MySQL의 I/O 대기 상태 확인
mysql -e "SHOW ENGINE INNODB STATUS\G" | grep -A 5 "FILE I/O"
# 어떤 프로세스가 I/O를 많이 쓰는지 확인
iotop -oP
해결 방법
- NVMe SSD로 교체 — 가장 효과적 (IOPS 100배 이상 향상)
innodb_flush_method = O_DIRECT설정으로 OS 캐시 이중화 방지innodb_io_capacity,innodb_io_capacity_max값을 SSD에 맞게 상향
# SSD 환경에 맞는 I/O 설정
innodb_flush_method = O_DIRECT
innodb_io_capacity = 2000
innodb_io_capacity_max = 4000
3. 슬로우 쿼리 누적
운영 초기에는 빨랐던 쿼리가 데이터가 쌓이면서 점점 느려지는 것은 매우 흔한 문제입니다. 인덱스 누락, 불필요한 풀 테이블 스캔이 주요 원인입니다.
슬로우 쿼리 로그 활성화
# /etc/mysql/mysql.conf.d/mysqld.cnf
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 1
log_queries_not_using_indexes = 1
분석 및 최적화
# 슬로우 쿼리 요약 (상위 10개)
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# 특정 쿼리의 실행 계획 확인
mysql -e "EXPLAIN SELECT * FROM orders WHERE user_id = 12345;"
# 인덱스 추가
mysql -e "ALTER TABLE orders ADD INDEX idx_user_id (user_id);"
# 현재 실행 중인 쿼리 확인
mysql -e "SHOW FULL PROCESSLIST;"
주의: 인덱스를 무작정 추가하면 INSERT/UPDATE 성능이 저하됩니다. EXPLAIN 결과를 확인한 뒤 필요한 인덱스만 추가하세요.
4. 커넥션 폭주 및 max_connections 초과
트래픽이 급증하거나 애플리케이션에서 커넥션을 제대로 반환하지 않으면 DB 접속이 거부됩니다.
증상
ERROR 1040 (HY000): Too many connections
진단
# 현재 커넥션 수 확인
mysql -e "SHOW STATUS LIKE 'Threads_connected';"
# 최대 커넥션 설정 확인
mysql -e "SHOW VARIABLES LIKE 'max_connections';"
# 어떤 호스트에서 많이 접속하는지 확인
mysql -e "SELECT host, COUNT(*) as cnt FROM information_schema.processlist GROUP BY host ORDER BY cnt DESC;"
해결 방법
# max_connections 상향 (기본값 151은 대부분 부족)
max_connections = 500
wait_timeout = 300
interactive_timeout = 300
근본 해결: 애플리케이션에서 커넥션 풀을 사용하세요. PHP는 pdo_mysql의 persistent connection, Node.js는 mysql2의 Pool, Python은 SQLAlchemy의 QueuePool 등을 활용합니다.
5. Lock 경합과 Deadlock
동시에 여러 트랜잭션이 같은 데이터를 수정하려 할 때 Lock 경합이 발생합니다. 심하면 Deadlock으로 트랜잭션이 강제 롤백됩니다.

진단
# InnoDB Lock 대기 상태 확인
mysql -e "SELECT * FROM information_schema.innodb_lock_waits\G"
# 최근 Deadlock 정보
mysql -e "SHOW ENGINE INNODB STATUS\G" | grep -A 30 "LATEST DETECTED DEADLOCK"
# Lock 대기 중인 쿼리 목록
mysql -e "SELECT * FROM sys.innodb_lock_waits\G"
해결 방법
- 트랜잭션 범위를 최소화 — 필요한 쿼리만 트랜잭션 안에
- UPDATE/DELETE 시 인덱스를 반드시 사용 (인덱스 없으면 테이블 전체 Lock)
- 여러 테이블을 수정할 때 항상 같은 순서로 접근
innodb_lock_wait_timeout값 조정 (기본 50초)
6. 백업 실패 및 복구 불가
“백업이 있다”와 “복구 가능한 백업이 있다”는 완전히 다릅니다. 실제로 복구를 시도하면 실패하는 경우가 많습니다.

mysqldump 백업 (소규모 DB)
# 전체 데이터베이스 백업
mysqldump --all-databases --single-transaction --routines --triggers \
--quick --lock-tables=false > /backup/full_$(date +%Y%m%d_%H%M%S).sql
# 특정 DB만 백업
mysqldump --single-transaction mydb > /backup/mydb_$(date +%Y%m%d).sql
# gzip 압축 백업
mysqldump --single-transaction mydb | gzip > /backup/mydb_$(date +%Y%m%d).sql.gz
xtrabackup (대규모 DB, 무중단 백업)
# Percona XtraBackup 전체 백업
xtrabackup --backup --target-dir=/backup/full/
# 증분 백업
xtrabackup --backup --target-dir=/backup/inc1/ \
--incremental-basedir=/backup/full/
# 복구 준비
xtrabackup --prepare --target-dir=/backup/full/
자동 백업 cron 설정
# /etc/cron.d/db-backup
# 매일 새벽 3시 전체 백업
0 3 * * * root mysqldump --all-databases --single-transaction | gzip > /backup/daily_$(date +\%Y\%m\%d).sql.gz
# 30일 이상 된 백업 자동 삭제
0 4 * * * root find /backup/ -name "*.sql.gz" -mtime +30 -delete
반드시 확인: 백업 후 정기적으로 복구 테스트를 실행하세요. 복구되지 않는 백업은 없는 것과 같습니다.
7. 보안 취약점
리눅스에서 직접 DB를 운영하면 보안 설정도 직접 해야 합니다. 기본 설정 그대로 두면 외부에서 침투당할 수 있습니다.
필수 보안 설정
# MySQL 보안 초기 설정 (설치 직후 실행)
mysql_secure_installation
# 외부 접속 차단 — bind-address 설정
# /etc/mysql/mysql.conf.d/mysqld.cnf
bind-address = 127.0.0.1
# 불필요한 원격 접속 계정 제거
mysql -e "SELECT user, host FROM mysql.user WHERE host != 'localhost';"
mysql -e "DROP USER 'root'@'%';"
# 방화벽으로 3306 포트 차단
ufw deny 3306
권한 최소화 원칙
-- 애플리케이션용 계정은 필요한 권한만 부여
CREATE USER 'webapp'@'localhost' IDENTIFIED BY 'strong_password_here';
GRANT SELECT, INSERT, UPDATE, DELETE ON mydb.* TO 'webapp'@'localhost';
-- SUPER, FILE, PROCESS 권한은 절대 애플리케이션에 부여하지 말 것
-- 관리 작업용 별도 계정 사용
8. 복제(Replication) 지연 및 장애
Master-Slave 구조에서 복제 지연이 발생하면 읽기 분산의 의미가 없어지고, 데이터 불일치 문제가 생깁니다.
복제 상태 확인
# Slave 서버에서 복제 상태 확인
mysql -e "SHOW SLAVE STATUS\G" | grep -E "Seconds_Behind|Running|Error"
# 핵심 확인 항목:
# Slave_IO_Running: Yes
# Slave_SQL_Running: Yes
# Seconds_Behind_Master: 0 (지연 없음)
복제 지연 해결
# Slave 서버 성능 튜닝
slave_parallel_workers = 4
slave_parallel_type = LOGICAL_CLOCK
slave_preserve_commit_order = 1
# Binary Log 포맷 설정 (ROW 권장)
binlog_format = ROW
9. 디스크 용량 부족
데이터베이스 파일, 바이너리 로그, 슬로우 쿼리 로그 등이 디스크를 꽉 채우면 DB가 갑자기 멈출 수 있습니다.
모니터링
# 디스크 사용량 확인
df -h /var/lib/mysql/
# MySQL 데이터 디렉토리 크기
du -sh /var/lib/mysql/
# 데이터베이스별 용량 확인
mysql -e "SELECT table_schema, ROUND(SUM(data_length + index_length) / 1024 / 1024, 2) AS 'Size (MB)' FROM information_schema.tables GROUP BY table_schema ORDER BY SUM(data_length + index_length) DESC;"
# 바이너리 로그 크기 확인
mysql -e "SHOW BINARY LOGS;"
해결 방법
# 오래된 바이너리 로그 삭제
mysql -e "PURGE BINARY LOGS BEFORE DATE_SUB(NOW(), INTERVAL 7 DAY);"
# 자동 삭제 설정
# /etc/mysql/mysql.conf.d/mysqld.cnf
expire_logs_days = 7
# MySQL 8.0+
binlog_expire_logs_seconds = 604800
10. 업그레이드 및 마이그레이션 문제
MySQL 5.7에서 8.0으로, 또는 MariaDB로 전환할 때 호환성 문제가 발생할 수 있습니다.
업그레이드 전 체크리스트
# MySQL 업그레이드 체커 실행
mysqlcheck --all-databases --check-upgrade
# MySQL 8.0 업그레이드 체커
mysql_upgrade_checker
# 현재 사용 중인 deprecated 기능 확인
mysql -e "SHOW WARNINGS;" 2>&1 | grep -i deprecated
# 현재 버전 확인
mysql -V
안전한 마이그레이션 순서
- 백업 — 반드시 풀 백업 후 복구 테스트까지 완료
- 스테이징 테스트 — 동일 환경에서 먼저 업그레이드 테스트
- 호환성 확인 — 쿼리 문법, 기본값 변경사항 확인
- 점검 시간 확보 — 충분한 유지보수 시간 확보 후 진행
- 롤백 계획 — 실패 시 원복 절차 준비
마무리 — 안정적인 DB 운영을 위한 핵심 원칙
| 원칙 | 설명 |
|---|---|
| 모니터링 자동화 | Prometheus + Grafana 또는 최소 cron + 알림 스크립트 |
| 백업 + 복구 테스트 | 백업만으로는 부족, 정기 복구 테스트 필수 |
| 보안 기본기 | bind-address, 방화벽, 권한 최소화 |
| 리소스 여유 확보 | CPU, 메모리, 디스크 모두 70% 이하 유지 |
| 변경 관리 | 설정 변경 전 반드시 백업, 기록, 테스트 |
리눅스 서버에서 데이터베이스를 안정적으로 운영하려면 지속적인 모니터링과 선제적 대응이 필수입니다. 문제가 발생한 뒤 대응하는 것보다, 미리 감지하고 예방하는 것이 훨씬 효과적입니다.
서버 환경에 맞는 최적의 DB 구성이 필요하시면 TCP-80.NET에 문의해 주세요. NVMe SSD 기반의 일본 서버에서 안정적인 데이터베이스 운영을 지원합니다.